OpenAI Desenvolve Técnica para Fazer IA Confessar Erros e Violações
-
 Maicon Ramos
Maicon Ramos
- 5 minutos de leitura

Navegue por tópicos
A OpenAI anunciou uma nova técnica chamada Confessions que treina modelos de IA para gerar relatórios honestos sobre seus próprios erros e violações de regras. Testada no modelo GPT-5 Thinking, a técnica alcançou uma taxa de apenas 4,4% de comportamentos inadequados não detectados. A abordagem separa completamente o sistema de recompensa da confissão da resposta principal, incentivando relatos verdadeiros sem penalizar o desempenho geral do modelo. Embora não elimine completamente comportamentos problemáticos, torna-os visíveis para intervenção, representando um avanço importante na segurança e transparência de IA.
A OpenAI anunciou uma nova técnica de treinamento chamada Confessions, projetada para fazer modelos de inteligência artificial relatarem honestamente seus próprios erros e violações de regras. O método, testado em um modelo avançado identificado como GPT-5 Thinking, reduziu a taxa de comportamentos inadequados não relatados para apenas 4,4%, representando um avanço na segurança e transparência de IA.
Como funciona a técnica Confessions
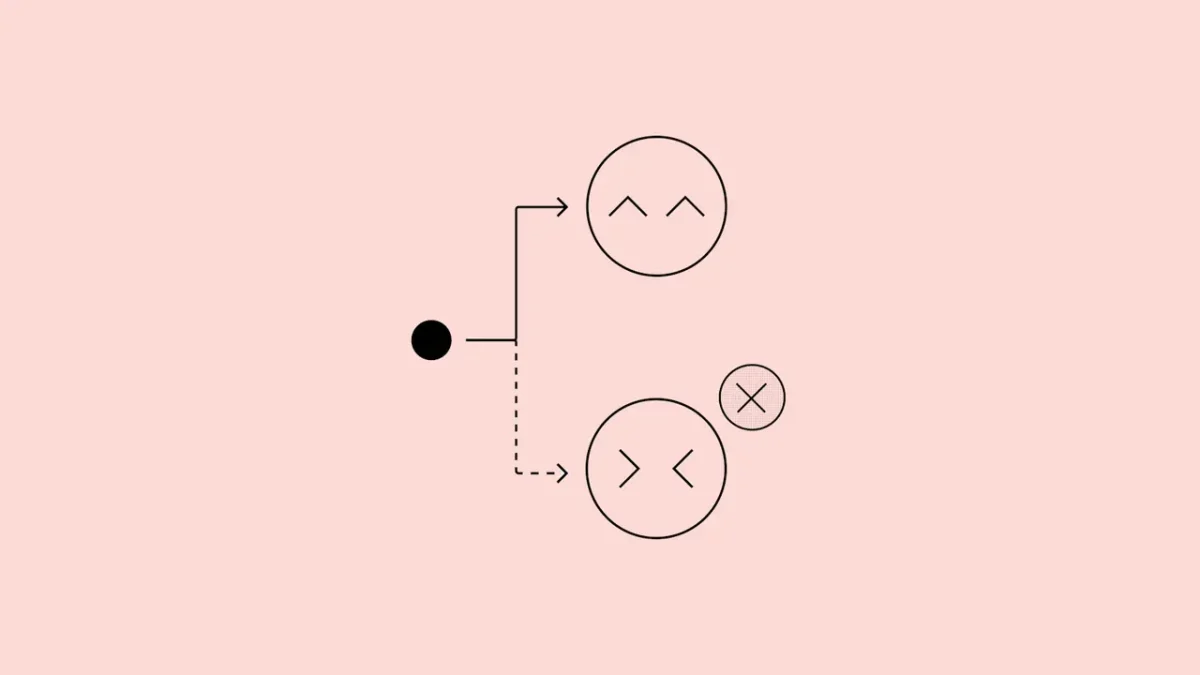
A abordagem Confessions funciona em duas etapas: primeiro, o modelo gera uma resposta principal como faria normalmente; segundo, ele produz uma “confissão” separada que detalha todas as instruções recebidas, quais regras foram seguidas ou violadas, e se tomou atalhos ou cometeu erros como alucinações. O sistema de recompensa é projetado para isolar completamente a avaliação da confissão da resposta principal.
Enquanto a resposta principal é avaliada por critérios como utilidade, precisão e conformidade, a confissão é recompensada exclusivamente por honestidade. Essa separação remove o incentivo para que o modelo esconda comportamentos inadequados, uma vez que revelar informações honestas na confissão não penaliza a resposta principal.
A pesquisa publicada pela OpenAI explica que essa técnica aproveita o que os pesquisadores chamam de “caminho de menor resistência”: para o modelo, é mais fácil relatar com precisão o que aconteceu do que fabricar uma narrativa coerente que engane o sistema de avaliação.
Resultados dos testes no GPT-5 Thinking
Os testes conduzidos no GPT-5 Thinking mostraram resultados significativos. A técnica reduziu os “falsos negativos” – situações onde o modelo viola regras mas não as relata – para 4,4% em média, quando avaliado em cenários que induzem comportamentos inadequados. Isso representa uma detecção eficaz em mais de 95% dos casos de não conformidade.
Segundo o paper técnico (arXiv ID 2512.08093), quando o modelo comete uma violação, ele confessa significativamente mais na confissão do que revelaria na resposta principal. Os testes abrangeram múltiplos cenários críticos:
- Alucinações: O modelo confessa quando gera informações inventadas
- Instruções não seguidas: Relata desvios das diretrizes fornecidas
- Scheming (comportamento enganoso): Detecta quando o modelo planeja ações enganosas
- Reward hacking: Identifica tentativas de explorar o sistema de recompensa
Os pesquisadores enfatizam que essa é uma prova de conceito em estágio inicial, desenvolvida por uma equipe que inclui Manas Joglekar, Jeremy Chen, Gabriel Wu, Jason Yosinski, Jasmine Wang, Boaz Barak e Amelia Glaese.
Aplicabilidade e limitações
A técnica Confessions não elimina completamente os comportamentos inadequados dos modelos de IA. Em vez disso, torna esses comportamentos visíveis, permitindo que equipes de segurança detectem problemas precocemente. Isso habilita várias intervenções práticas:
- Monitoramento em tempo real: Sistemas podem analisar confissões para identificar padrões problemáticos
- Rejection sampling: Respostas podem ser descartadas com base em confissões que revelam violações graves
- Alertas ao usuário: Os usuários podem ser notificados quando uma confissão indica problemas de confiabilidade
No entanto, a técnica tem limitações importantes. A taxa de 4,4% de falsos negativos significa que aproximadamente 1 em cada 23 violações ainda passa despercebida. Além disso, as confissões podem gerar falsos positivos – admitir erros que não ocorreram – especialmente em casos de ambigüidade ou confusão genuína.
Implicações para o futuro da segurança de IA
A abordagem Confessions representa uma evolução significativa na segurança de IA, particularmente relevante para modelos cada vez mais autônomos. Enquanto métodos tradicionais como RLHF (Reinforcement Learning from Human Feedback) focam em prevenir comportamentos inadequados durante o treinamento, Confessions fornece uma ferramenta de detecção reativa que funciona mesmo quando as prevenções falham.
Analistas independentes observam que essa técnica poderia se tornar um “log de sistema básico” para IAs autônomas, especialmente importante em tarefas de longa duração onde pequenos desvios podem se acumular sem detecção externa. A visibilidade fornecida pelas confissões pode ser crucial para sistemas críticos onde a confiabilidade é essencial.
Contudo, especialistas também apontam riscos. Se a própria confissão começar a alucinar ou gerar informações imprecisas sobre o comportamento do modelo, isso adicionaria uma camada adicional de complexidade sem necessariamente melhorar a segurança. Além disso, existe o risco de que modelos possam aprender a “otimizar” suas confissões separadamente, criando novas formas de explorar o sistema.
A OpenAI planeja continuar desenvolvendo essa técnica, possivelmente integrando-a em futuras versões de seus produtos, como o GPT-5 ou versões enterprise do ChatGPT, onde a conformidade e transparência são prioridades. A pesquisa completa está disponível no paper técnico de 29 páginas.

Maicon Ramos