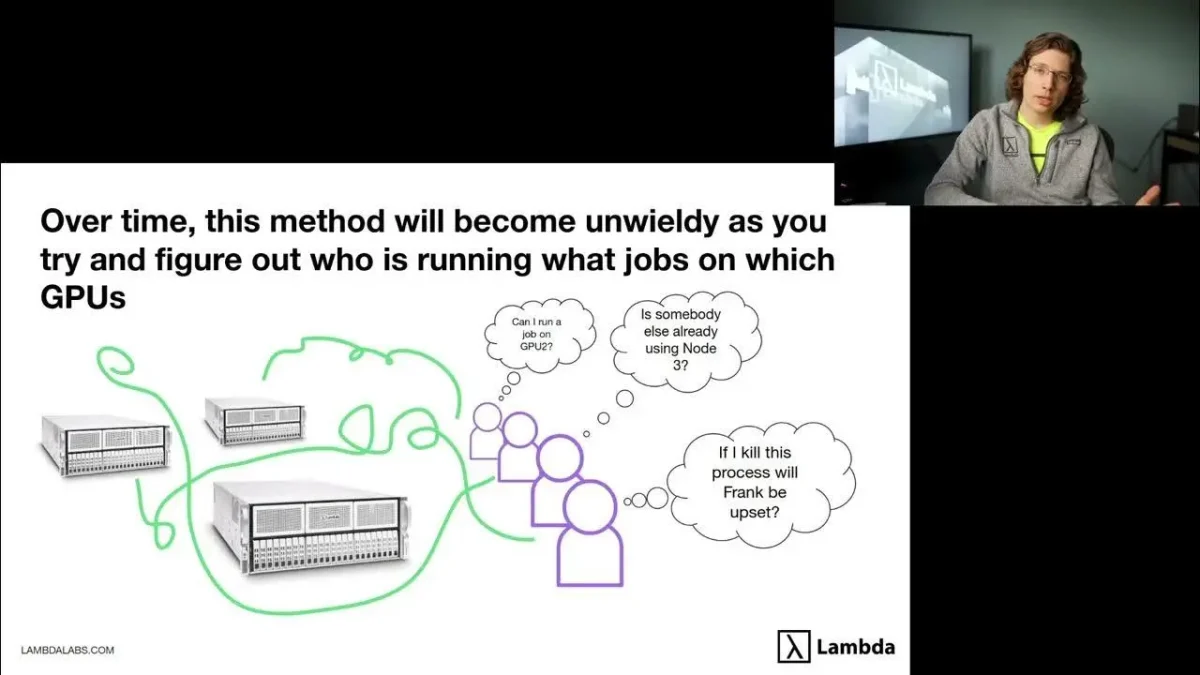
Lambda Labs desenvolveu um playbook para maximizar a eficiência do uso de hardware em treinamentos de IA, focando em GPUs on-premise como A100 e A6000.
Aborda ineficiências de memória, comunicação entre GPUs e configurações de treinamento.
Promete ganhos superiores a 25% de eficiência e redução de custos em comparação ao cloud.
Aplicável a setups desde workstations até clusters com dezenas de GPUs.
Lide: Playbook para eficiência em IA
Lambda Labs, empresa referência em infraestrutura para machine learning, lançou o Lambda’s Playbook, um guia que oferece estratégias para otimizar o uso de recursos computacionais durante treinamentos de inteligência artificial (IA). Disponível desde fevereiro de 2022, o documento volta a ganhar destaque em 2026 diante da persistente subutilização de GPUs em treinamentos de grandes modelos.
Detalhes do Playbook
O playbook aborda principalmente três gargalos:
Ineficiências de memória: Má alocação e gerenciamento da memória das GPUs que reduz a capacidade máxima de processamento.
Configurações de treinamento inadequadas: Parâmetros subótimos que prejudicam o throughput e elevam consumo de recursos.
Comunicação entre GPUs: Lentidão e filas ineficientes na troca de dados durante treinamento.
Como resultado, a Lambda recomenda o uso de GPUs on-premise como A100 e RTX A6000, que combinam performance superior e custo-benefício em comparação à nuvem pública, especialmente em clusters de larga escala para LLMs. Benchmarks com o modelo BERT-large no dataset SQuAD mostram acelerações expressivas, com a A100 superando GPUs V100 como baseline.
Escalabilidade e Aplicações
O framework é desenhado para evoluir desde setups simples com uma GPU (como laptops TensorBook) até clusters densos com 64 ou mais GPUs integradas via Infiniband. O playbook prioriza:
Incrementar capacidade de computação aos poucos conforme a equipe cresce.
Uso de filas dinâmicas para minimizar ociosidade e maximizar uso dos recursos.
Preparação cuidadosa dos dados, com retraining baseado em feedback de inferência.
Comparação de Setups
Estágio
Hardware Recomendado
Throughput (BERT-large/SQuAD)
Custo vs. Cloud
Início (1-2 GPUs)
Laptop TensorBook
Baseline V100
30-50% menos
Equipe pequena (2-8 GPUs)
Workstation A6000
Superior à V100
Savings significativos
Escala (64+ GPUs)
Cluster Infiniband H100/A100
Otimizado para LLMs
Foco em AI factories on-premise
Críticas e Limitações
Apesar dos ganhos, o manual impõe algumas limitações:
Alto investimento inicial para montagem de infraestrutura on-premise robusta, incluindo requisitos avançados de energia e cooling para densidade de até 240 kW por rack.
Dependência de GPUs high-end que ainda enfrentam escassez de disponibilidade em data centers prontos para IA.
Orquestração complexa que demanda equipe especializada para manipular filas dinâmicas e tuning fino.
Benchmarks focados em NLP com BERT/SQuAD; resultados para IA generativa (diffusion, vídeo) podem variar.
Impacto e Perspectivas
A iniciativa da Lambda Labs democratiza o acesso a práticas avançadas para maximizar a eficiência do hardware em machine learning, especialmente para equipes que optam por ambientes on-premise em vez de cloud. Isso pode resultar em redução de custos e maior rapidez em treinamentos, mas exige investimento e conhecimento significativo.
O playbook representa a continuidade de uma tendência em consolidar data centers com alta densidade para IA, conforme discutido em sua apresentação oficial com vídeo e slides disponíveis no site da Lambda e em plataformas como Scale Exchange.